
As part of my Master’s Programme requirement for MSIS, I am required to form a team of 3 members and select a topic to write about. Our team had a strong interest in applying what we learnt about artificial intelligence (AI) and deep learning. Thus, we picked the topic of understanding Singaporeans’ attitudes towards racial issues through aspect-based sentiment analysis (ABSA). The data are collected from the local popular social media platforms Hardwarezone forum and Reddit, from 2017 to 2022. Using deep learning BERT-based machine learning model, we seek to analyse sentiments shared among netizens in Singapore on racial-related issues. Sentiment analysis will be based on the data collected, to understand Singaporeans’ attitudes towards racial issues and how the trend has shifted.
Sentiment analysis algorithms obtain sentiments and opinions from natural languages by sentence or document level (Wilson et al., 2009). However, certain sentences may have different aspects, and the sentiment polarities for each aspect may be different as well. For example, the sentence “while the level of customer service was excellent, the quality of the food was horrible” contains two aspects, food quality and customer service. While both aspects are related, they illustrate the two opposite sentiments, and the sentiment analysis algorithms may not pick up all the aspects. ABSA is a more specialised Natural Language Processing (NLP) algorithm. It picks the sentiment polarities of various aspects within the same sentence (Zeng et al., 2019) and seeks to predict targeted aspects’ sentiment polarities in the same sentence.
Aspect-based sentiment classification (ABSC) is used to obtain different aspects’ sentiments in the same sentence. Algorithms that are based on Deep Neural Networks (DNN) such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN), focus on analysing the relations between the global context (whole sentence) and sentiment polarity (Zeng et al., 2019). However, they failed to distinguish the relations between the local context and the targeted aspect’s sentiment polarity. For better performance, the Local Context Focus (LCF) BERT model is used. LCF-BERT does not only focus on global text but also focuses on words which are located around the aspect term. These words around the aspect term (such as adverbs and adjectives) are significantly more influential. On the other hand, words which are further away from the aspect term have a negative influence when determining the polarities of the targeted aspects (Zeng et al., 2019).
Results of the Dataset

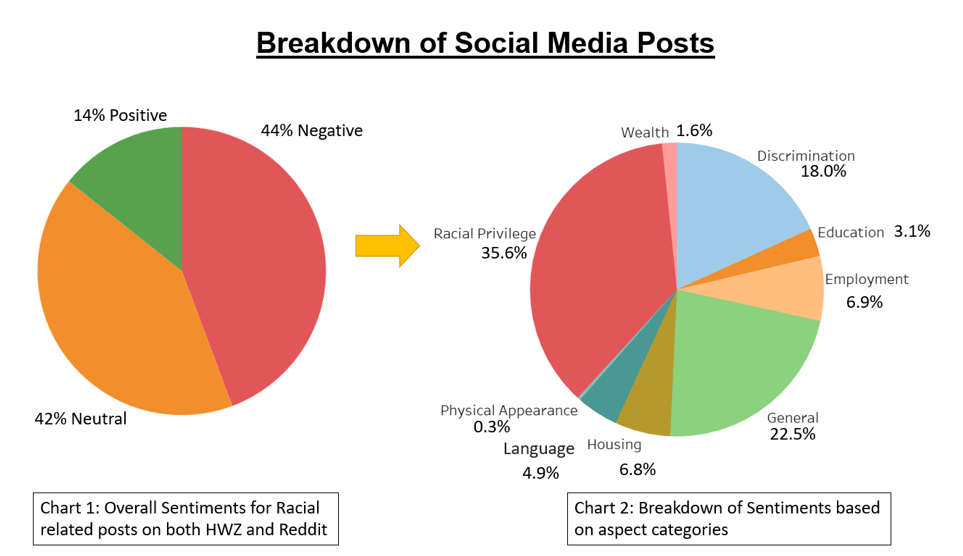
From the sentences extracted from HWZ and Reddit that contains racial-related statements, chart 1 shows that the slight majority of the sentences contain negative sentiments making up 44% sentences, followed closely by neutral sentiments 42% sentences. Only the minority 14% sentences contain positive sentiments. Diving down further, chart 2 illustrates the breakdown of the sentences into 10 aspect categories. The top 3 aspect categories with the most racial-related sentences are racial privileges, general and discrimination.

Chart 3 shows the top 10 most concerned aspect terms in both forums, which made up 68% of the sentences extracted, with “Chinese privilege” leading to the top by a large gap compared to other aspects. In addition, the “Chinese privilege” is highly associated with the “majority privilege” as the Chinese race made up the majority race in Singapore and the topics discussed mostly revolved around the majority race having certain advantages over other races. Another major aspect to highlight is the CECA, which brings strong sentiments in the forums arising from the foreign Indian workers working here.
Analysis of Trends of Sentiment In Racial Related Issues
Next, analysing from the top 10 aspects from chart 3, chart 5 provides the breakdown count for each aspect based on their sentiment polarity, with -1 representing negative sentiments, 0 representing neutral and 1 representing positive. Positive sentiment forms the minority for all the 10 aspects. On the other hand, there is variation between negative and neutral sentiments for all the aspects. For a more complete analysis of the overall sentiment for each of the aspect terms, we take reference from the work of Fan’s Public opinion analysis about nuclear energy by using the aspect‑based sentiment analysis techniques (Fan, 2022, 32), and applied the parameter to our sentiment calculations called Racial Opinion Index (ROI), to quantify the general public’s opinions on specific topics/aspects and their changes. The parameter m of the formula represents the particular aspect or the combination of several aspects, while N means the number of designated parameters.

Sentiment Trend Analysis
The count of each polarity is then used to compute the ROI in Table 9, returning the ROI values from 1 (extremely positive) to 200 (extremely negative) as explained above. A point to note is that while 200 is the maximum threshold for negative sentiment, the values in this case do not necessarily mean that the aspect category reached the maximum suggesting that the public had “extreme resentment” for that category. This is likely due to the limited aspect category data collected, like “language”, “physical appearance” and even “racial privilege”.

RESULTS OF LCF-BERT MODEL TRAINING

Weighted F1-Score
The Weighted section calculates F1-scores of the test dataset containing all sentiment polarities. For the entire test dataset, the F1-score is 0.651. Since F1-Score is obtained from the harmonic mean of each Precision and Recall score, it is worthwhile to inspect the Precision and Recall score. The weighted Recall and Precision scores for the entire test dataset are 0.655 and 0.670 respectively. Therefore, the model train is capable of retrieving many relevant items, and many of the items retrieved are relevant. Chart 11 shows that discrimination, education and general categories outperform other categories by with the F1-score of 0.80, 0.72 and 0.70 respectively. Discrimination and general category have a larger dataset size (refer to table 6), therefore providing more examples for the model for both training and testing leading to higher F1-scores.
On the other hand, although the Racial Privilege category has a large dataset size, its weighted F1-score is low at 0.55. By inspecting its individual sentiment category, it has less data in its positive sentiment hence having a lower F1-score (at 0.37 for Racial Privilege Positive Sentiment) and pulling down its overall F1-score. For the remaining categories, it is reasonable that their weighted F1-score are low (below 0.6) since their dataset size is small.
F1-Score by Sentiment Polarities
Negative Sentiment – Since we have a higher ratio of our dataset labelled as negative sentiment, it is reasonable that the F1-score for all categories are high (above 0.6) except for the language category. The low F1-score of the Language category can be attributed to its low sample size.
Neutral Sentiment – The dataset labelled as neutral sentiment is the second highest after the negative sentiment. Therefore, there are also more examples provided to the model in comparison to the positive sentiment section. In general, the F1-score for all categories with neutral sentiment is high (above 0.6). The only category having a low F1-Score is employment (at 0.48), which can be attributed to its low sample size.
Positive Sentiment – Since the dataset consists of very few examples labelled with positive sentiment, the model is trained with additional data using the “Laptop” and “Restaurant” datasets provided by Zeng et al. (2019) and Song (2021). This could contribute to the dilution of the dataset. For example, the model is unable to predict racial-related and positive sentiment correctly due to this dilution. In general, only those categories with large dataset size (discrimination and general categories) have high F1 scores at 0.76 and 0.82 respectively, while the remaining categories have low F1-score which are below 0.6.
CONCLUSION
Racial issues are sensitive and complex that are not openly discussed in public in Singapore. The people are more comfortable questioning, and expressing their opinions and sentiments towards these issues on social media as there is some form of anonymity, giving them some sense of “safety”. From our process of web scraping from HWZ and Reddit, the large volume of collected data being filtered in different stages increased the difficulty for us to build a sufficiently clean dataset for deep learning. The data left are highly skewed towards the negative sentiments and have to be supplemented by other datasets to be balanced for proper deep learning.
LCF-BERT model is trained using racial-related sentences, supplemented by Restaurant and Laptop dataset provided by Zeng et al. (2019) and Song (2021). The optimum model trained has the following parameters: learning rate of 5e-0.5, drop out of 0, L2 regularisation of 0.00001, batch size of 16, epochs of 2, embed size of 768, hidden size of 768, local context focus is CDW, and SRD of 3. The weighted F1-score of the test dataset is 0.651. Since F1-Score is obtained from the harmonic mean of the Precision and Recall, individual Precision and Recall scores are obtained as well. The weighted Recall and Precision are 0.655 and 0.670 respectively. Therefore, the model train is capable of retrieving many relevant items and many of its items retrieved are relevant.
The analysis shows the trends of increasing negative sentiments, especially for the last 3 years, and this is consistent with the racial-related survey. However, the underlying categories showed different interesting findings. The negative sentiments around racial issues are mostly external factors such as employment, education and housing. These extrinsic factors are monitored by the Singapore Government closely and often debated for the benefit of the economy. No deep-rooted hatred and misunderstanding about other races are discussed in the dataset. This does not discount the fact that extreme racial prejudice may be filtered out by the social media administrators.
The forum posters often discussed and questioned the “Chinese majority privileges”, but their underlying sentiments are largely mild which could be the reason behind their beliefs in the future having lesser racism. For the aspect categories such as “employment” where the posters felt a threat, they expressed strong resentment against the foreign talents, especially where terms like “CECA” were brought up. They tend to direct the negative sentiments to the government policies in these areas by describing words like “policies”, “system” etc. On a positive note, the other important categories such as “housing” and “education” related issues show mild negative sentiments. Overall, the analysis provides a good sense of direction of which racial aspect category to prioritise for improvement.